 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhySE: A Psychological Framework for Real-Time AR-LLM Social Engineering Attacks
Apr 25, 2026The emerging threat of AR-LLM-based Social Engineering (AR-LLM-SE) attacks (e.g. SEAR) poses a significant risk to real-world social interactions. In such an attack, a malicious actor uses Augmented Reality (AR) glasses to capture a target visual and vocal data. A Large Language Model (LLM) then analyzes this data to identify the individual and generate a detailed social profile. Subsequently, LLM-powered agents employ social engineering strategies, providing real-time conversation suggestions, to gain the target trust and ultimately execute phishing or other malicious acts. Despite its potential, the practical application of AR-LLM-SE faces two major bottlenecks, (1) Cold-start personalization, Current Retrieval-Augmented Generation (RAG) methods introduce critical delays in the earliest turns, slowing initial profile formation and disrupting real-time interaction, (2) Static Attack Strategies, Existing approaches rely on fixed-stage, handcrafted social engineering tactics that lack foundation in established psychological theory. To address these limitations, we propose PhySE, a novel framework with two core innovations, (1) VLM-Based SocialContext Training, To eliminate profiling delays, we efficiently pre-train a Visual Language Model (VLM) with social-context data, enabling rapid, on-the-fly profile generation, (2) Adaptive Psychological Agent, We introduce a psychological LLM that dynamically deploys distinct classes of psychological strategies based on target response, moving beyond static, handcrafted scripts. We evaluated PhySE through an IRB-approved user study with 60 participants, collecting a novel dataset of 360 annotated conversations across diverse social scenarios.
UNSEEN: A Cross-Stack LLM Unlearning Defense against AR-LLM Social Engineering Attacks
Apr 25, 2026Emerging AR-LLM-based Social Engineering attack (e.g., SEAR) is at the edge of posing great threats to real-world social life. In such AR-LLM-SE attack, the attacker can leverage AR (Augmented Reality) glass to capture the image and vocal information of the target, using the LLM to identify the target and generate the social profile, using the LLM agents to apply social engineering strategies for conversation suggestion to win the target trust and perform phishing afterwards. Current defensive approaches, such as role-based access control or data flow tracking, are not directly applicable to the convergent AR-LLM ecosystem (considering embedded AR device and opaque LLM inference), leaving an emerging and potent social engineering threat that existing privacy paradigms are ill-equipped to address. This necessitates a shift beyond solely human-centric measures like legislation and user education toward enforceable vendor policies and platform-level restrictions. Realizing this vision, however, faces significant technical challenges: securing resource-constrained AR-embedded devices, implementing fine-grained access control within opaque LLM inferences, and governing adaptive interactive agents. To address these challenges, we present UNSEEN, a coordinated cross-stack defense that combines an AR ACL (Access Control Layer) for identity-gated sensing, F-RMU-based LLM unlearning for sensitive profile suppression, and runtime agent guardrails for adaptive interaction control. We evaluate UNSEEN in an IRB-approved user study with 60 participants and a dataset of 360 annotated conversations across realistic social scenarios.
SEAR: A Multimodal Dataset for Analyzing AR-LLM-Driven Social Engineering Behaviors
May 30, 2025The SEAR Dataset is a novel multimodal resource designed to study the emerging threat of social engineering (SE) attacks orchestrated through augmented reality (AR) and multimodal large language models (LLMs). This dataset captures 180 annotated conversations across 60 participants in simulated adversarial scenarios, including meetings, classes and networking events. It comprises synchronized AR-captured visual/audio cues (e.g., facial expressions, vocal tones), environmental context, and curated social media profiles, alongside subjective metrics such as trust ratings and susceptibility assessments. Key findings reveal SEAR's alarming efficacy in eliciting compliance (e.g., 93.3% phishing link clicks, 85% call acceptance) and hijacking trust (76.7% post-interaction trust surge). The dataset supports research in detecting AR-driven SE attacks, designing defensive frameworks, and understanding multimodal adversarial manipulation. Rigorous ethical safeguards, including anonymization and IRB compliance, ensure responsible use. The SEAR dataset is available at https://github.com/INSLabCN/SEAR-Dataset.
On the Feasibility of Using MultiModal LLMs to Execute AR Social Engineering Attacks
Apr 16, 2025Augmented Reality (AR) and Multimodal Large Language Models (LLMs) are rapidly evolving, providing unprecedented capabilities for human-computer interaction. However, their integration introduces a new attack surface for social engineering. In this paper, we systematically investigate the feasibility of orchestrating AR-driven Social Engineering attacks using Multimodal LLM for the first time, via our proposed SEAR framework, which operates through three key phases: (1) AR-based social context synthesis, which fuses Multimodal inputs (visual, auditory and environmental cues); (2) role-based Multimodal RAG (Retrieval-Augmented Generation), which dynamically retrieves and integrates contextual data while preserving character differentiation; and (3) ReInteract social engineering agents, which execute adaptive multiphase attack strategies through inference interaction loops. To verify SEAR, we conducted an IRB-approved study with 60 participants in three experimental configurations (unassisted, AR+LLM, and full SEAR pipeline) compiling a new dataset of 180 annotated conversations in simulated social scenarios. Our results show that SEAR is highly effective at eliciting high-risk behaviors (e.g., 93.3% of participants susceptible to email phishing). The framework was particularly effective in building trust, with 85% of targets willing to accept an attacker's call after an interaction. Also, we identified notable limitations such as ``occasionally artificial'' due to perceived authenticity gaps. This work provides proof-of-concept for AR-LLM driven social engineering attacks and insights for developing defensive countermeasures against next-generation augmented reality threats.
A Map-matching Algorithm with Extraction of Multi-group Information for Low-frequency Data
Sep 18, 2022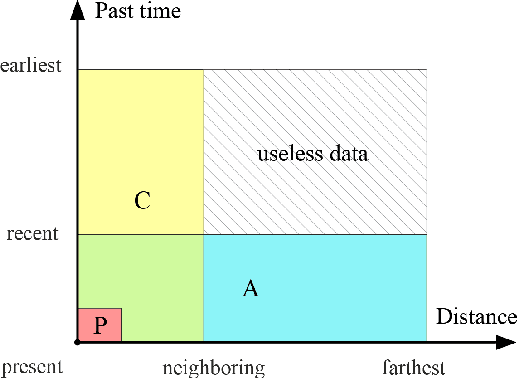
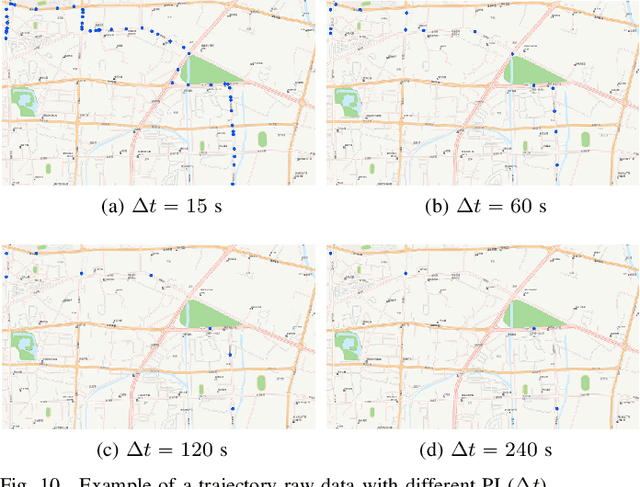
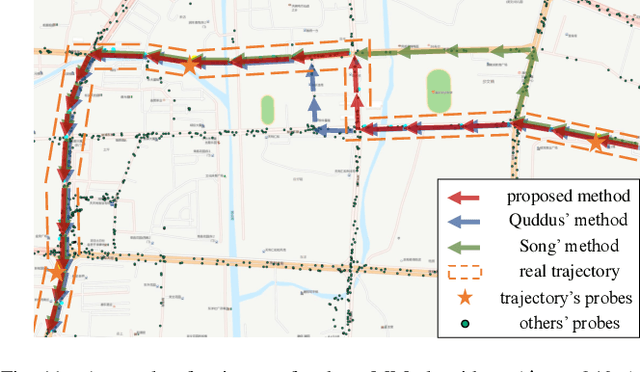
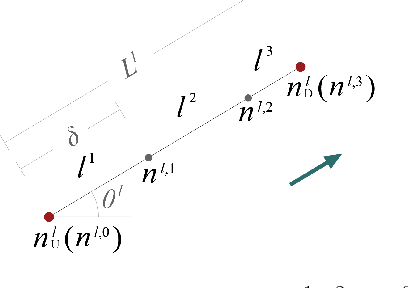
The growing use of probe vehicles generates a huge number of GNSS data. Limited by the satellite positioning technology, further improving the accuracy of map-matching is challenging work, especially for low-frequency trajectories. When matching a trajectory, the ego vehicle's spatial-temporal information of the present trip is the most useful with the least amount of data. In addition, there are a large amount of other data, e.g., other vehicles' state and past prediction results, but it is hard to extract useful information for matching maps and inferring paths. Most map-matching studies only used the ego vehicle's data and ignored other vehicles' data. Based on it, this paper designs a new map-matching method to make full use of "Big data". We first sort all data into four groups according to their spatial and temporal distance from the present matching probe which allows us to sort for their usefulness. Then we design three different methods to extract valuable information (scores) from them: a score for speed and bearing, a score for historical usage, and a score for traffic state using the spectral graph Markov neutral network. Finally, we use a modified top-K shortest-path method to search the candidate paths within an ellipse region and then use the fused score to infer the path (projected location). We test the proposed method against baseline algorithms using a real-world dataset in China. The results show that all scoring methods can enhance map-matching accuracy. Furthermore, our method outperforms the others, especially when GNSS probing frequency is less than 0.01 Hz.